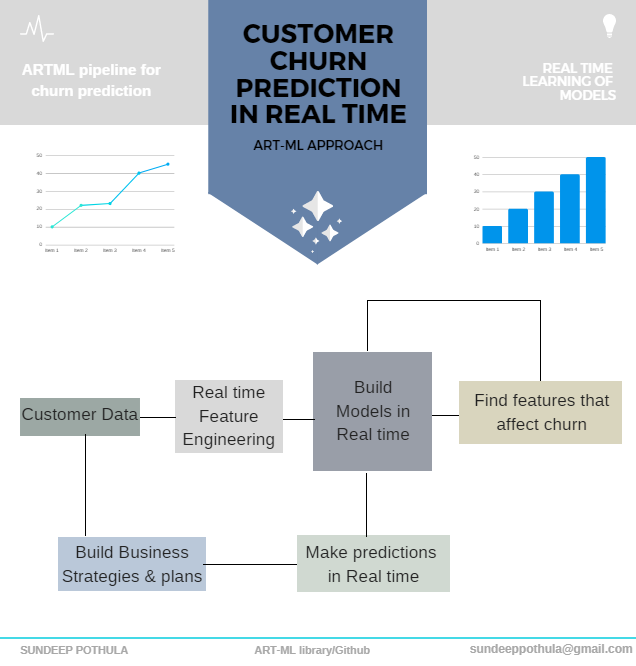
Real time learning for predicting Customer Churn
Churning (or) customers leaving a company for the competition is one of the most important challenges faced by most of the enterprises. Businesses in the consumer market have to deal with churn else it will directly impacts on company revenue. By effectively predicting the customers who will churn, companies can take necessary actions in order to retain customers.
Although there are many machine learning techniques that are used now to predict customer churn, these techniques have a number of limitations like:
- They tend to be batch-based: all the data to be used for the modeling must be available upfront for the model construction and many of them cannot work incrementally, i.e., incorporate into the model information arrived after it has been built; the model construction is computationally costly.
- Reasons for customer churn in the market is highly and unpredictably dynamic and depends on factors that change from time to time in reaction to market conditions, product or price changes, or sociological phenomena. Hence model should be able to add and delete effect of features in the model on fly in real time.
- Model should have the power to automatically identify the best features that cause churn in real time and should be able to make the changes in real time instead of training the whole data.
The problem is more critical in sectors such as the telecom markets (say, companies to which customers subscribe for mobile phone service), which are affected by high customer churn rate. Telcos also face the challenge of dealing with large amounts of information generated by the mobile users every second.
In this context, models built earlier in the past can quickly or gradually get out of sync with the current customer patterns, resulting in suboptimal churn prediction rate and therefore revenue loss. This is one of the main concerns in many enterprises today. An obvious solution is to rebuild the models periodically (like every other day or week), but this typically either requires human analyst time (which is slow and expensive) or automatizing decisions such as when and on which amount data to retrain new models and what features to be selected for model training.
ARTML for predicting Customer Churn
ARTML with its power to build the models in real time and with its capacity to accomodate huge amounts of data patterns can help solve this problem. This can also find the best features that impacts the model in real time and can rebuild the model accordingly on the fly by deleting and adding the features for making predictions. Also, they can respond to business events the moment they happen, rather than acting on them retrospectively. ARTML also has the power to run on Distributed processing systems to improve processing speeds and to accomodate huge data. By using artml predictive analytics, companies can differentiate from their competitors by taking real time decisions.
Let us see how we can use artml for predicting Customer Churn in real time. Code for this real time pipeline is provided in this Jupyter notebook
Data preparation
Customer Data gathered in real time can be preprocessed and feature engineering can be performed as required. Suppose if the dataset is having high dimensional features then even PCA can be applied in real time (use PCA function in artml library).
For this blog post example, a sample customer churn dataset is gathered from IBM_repository
Data Exploration
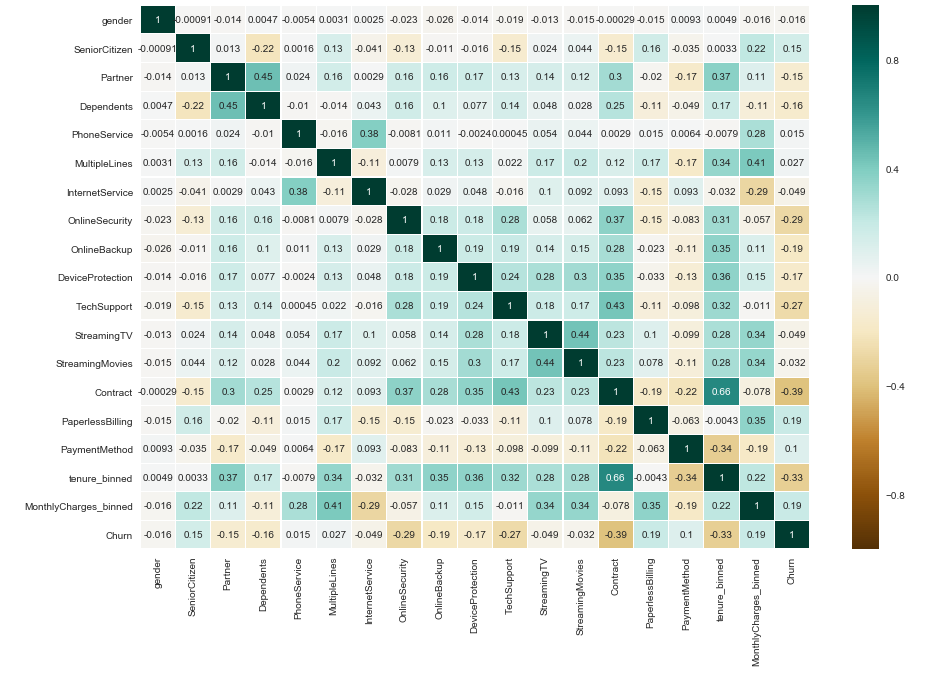
Univariate & Bivariate statistics for the data can be calculated in realtime. Also correlation heatmaps plotted from artml functions help us to identify features that are highly correlated. (This heatmap is updated in realtime as we get new labelled data)
Modeling
Linear discriminant analysis (LDA model) which gives good accuracies in most of the cases is chosen for making predictions about the Customer churn detections. LDA Model is imported from artml library and trained with the data. Code
In most of the cases customer data is very huge and not all features can be used for making churn predictions. In all the traditional ML approaches feature selection is done when the model is initially built combined with the domain knowledge. But as time progresses there might be some new variables which are significant for churn prediction. The reason is that churn is a temporal effect and the factors contributing to churn are usually in transient states. What leads a customer to consider leaving today might be different tomorrow, and it certainly will be different six months from now. Therefore, features in the model needs to be updated in realtime.
Conventional ML approaches lack the true power of feature selection because model cannot be updated to consider new set of features time to time. using artml we can use the exsisting model for selecting the best features and then update the model based on these features to make better predictions. this process is continous and model gets upgraded everytime to always make best decisions.
We are performing feature selection using lda model, precisely by calculating mahalanobis distance for different features in predicting the target. Read documentation to know more about how to implement these.
Model Evaluation
The acuracy of the basic model is 80.075% even without any feature engineering. However, the most important metric in churn is the misclassification rate: that is, of the top N churners as predicted by the classifier, which of them actually did not churn, and yet received special treatment? or who are the customers that we didnt predict and still on churn. AUC curve shows the misclassification rate which is found to be approx. 74% which is good considering the tradtional standards. Also, specificity of model which is 87.459% shows that in 87.46% of the cases we were able to predict customer churn in real time which shows the power of the model. Using thse predictions special plans can be provided for the target customers to reduce churn rate.
The model perfomance can be further improved when new features are created with feature engineering techniques combined with domain knowledge.
Deployment in Realtime
As the new labelled data gets generated, The model perfomance can be improved by training the model with new data and by deleting the effects of old data in the model in real time. Learn and forget functions in artml library helps to update BET in real time with the data. Once the BET table gets updated then the model is automatically upgraded on the fly. Also, artml library has the power to incorporate and delete certain features in the model in real time. As we are updating the effect of new data into the model we can perform real time feature selection using arml and hence update the model with new features whenever required. Although we can use Forget and Learn functions for training model with data in real time, What data to be added to the model and what data needs to be deleted should be decided based on domain knowledge and also by checking model perfomance Use learn, forget, grow, delete and feature_selection functions from artml library for performing these tasks.
Discussion
All the steps mentioned above can be automated in an pipeline which makes the process self sustaining. This mentioned framework is appied only on a sample dataset. We look foward to apply this in real scenario on a Big data. The model and tasks can be built even better for each specific Business case making it more powerful. Contact us for any Industrial consultations.